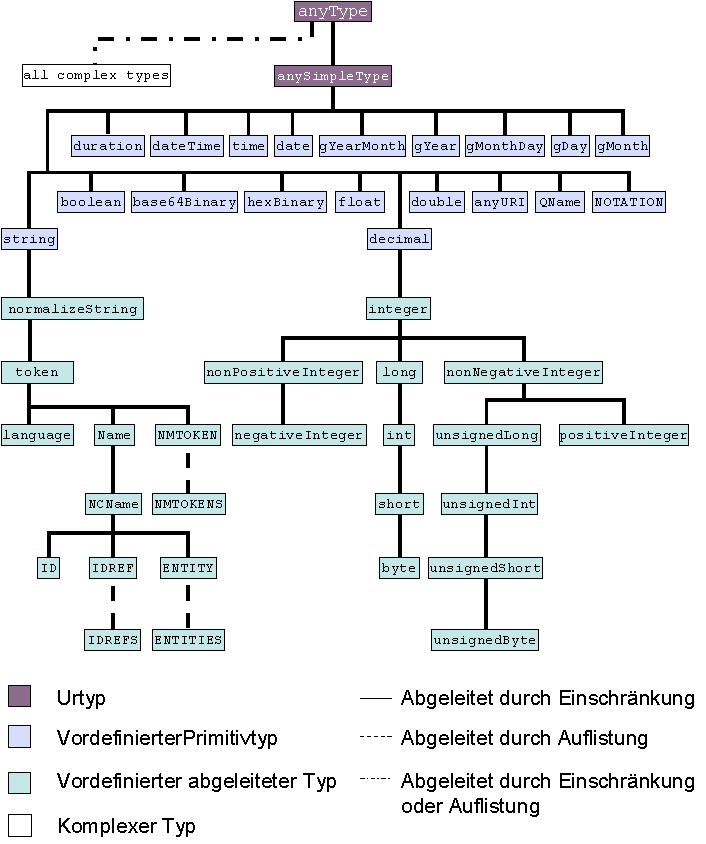
Alle vordefinierten Datentypen aus dieser Spezifikation (sowohl die
primitiven als auch die abgeleiteten) können durch eine eindeutige
URI-Referenz adressiert werden, die wie folgt aufgebaut ist:
Zusätzlich lässt sich jedes Element, das eine Fassette eines Datentyps
definiert, ebenfalls durch einen eindeutigen URI adressieren, der wie
folgt aufgebaut ist:
Die Adressierung der maxInclusive-Fassette sieht z. B. folgendermaßen aus:
Analog läßt sich jede Verwendung einer Fassette in einer vordefinierten
Datentypdefinition durch einen eindeutigen URI adressieren, der
folgendermaßen aussieht:

 3.2 Primitive Datentypen
3.2 Primitive Datentypen
Die in dieser Spezifikation definierten primitiven Datentypen werden
im Folgenden näher erläutert. Zu jedem Datentyp wird dessen
Wertebereich und lexikalischer Bereich definiert, einschränkende
Fassetten aufgeführt und jeder davon abgeleitete Datentyp wird spezifiziert.
Das Hinzufügen weiterer primitiver Datentypen ist nur durch neue
Versionen dieser Spezifikation möglich.
3.2.1 string
[Definition:]
Der Datentyp string repräsentiert Zeichenketten in
XML. Der Wertebereich des Datentyps
string ist die Menge von
Sequenzen endlicher Länge von
Zeichen (wie in [XML 1.0 (Second Edition)] definiert), die der Char-Produktion aus
[XML 1.0 (Second Edition)]
entsprechen. Ein Zeichen ist eine atomare
Kommunikationseinheit und ist nicht genauer spezifiziert, außer anzumerken,
dass jedes Zeichen zu einer Kodierung des Universal
Character Sets korrespondiert, die jeweils durch eine ganze Zahl vom Typ Integer dargestellt wird.
Anmerkung:
Viele Sprachen besitzen Schriftsysteme, in denen Kindelemente benötigt werden, um zum Beispiel
Aspekte wie das bidirektionale Formatieren oder Ruby-Annotationen (siehe
[Ruby] und Abschnitt 8.2.4
Überschreiben des bidirektionalen Algorithmus: das BDO Element) zu
steuern.
Als einfacher Datentyp, der nur Zeichen und keine Kindelemente enthalten kann, ist
string daher oft zur Darstellung von Texten nicht geeignet.
In
solchen Fällen sollte stattdessen ein komplexer Datentyp benutzt
werden, der ein gemischtes Inhaltsmodell zulässt. Weitere Informationen findet
man in Abschnitt 5.5
Any Element, Any Attribut der
[XML Schema Language: Part 2 Primer].
Anmerkung:
Wie in
geordnet angemerkt, bedeutet die Tatsache, dass diese Spezifikation keine
Ordnungsbeziehung auf den Datentyp
string definiert, nicht, dass
Anwendungen Zeichenketten als nicht geordnet behandeln müssen.
3.2.2 boolean
[Definition:]
Der Wertebereich von boolean dient dazu, das
mathematische Konzept einer zweiwertigen Logik abzubilden:
{true, false}.
3.2.2.1 Lexikalische Repräsentation
Eine Instanz des Datentyps boolean kann durch die gültigen Literale
{true, false, 1, 0} beschrieben werden.
3.2.2.2 Kanonische Repräsentation
Die kanonische Repräsentation für boolean ist die Menge
der Literale {true, false}.
3.2.3 decimal
[Definition:]
Der Datentyp decimal stellt Dezimalzahlen beliebiger
Genauigkeit dar. Der Wertebereich von decimal ist die Menge aller
Werte i × 10^-n,
wobei i und n ganze Zahlen sind mit n >= 0. Die Ordnungsbeziehung auf den Datentyp decimal lautet: x < y wenn y - x positiv ist.
[Definition:]
Der Wertebereich eines von decimal abgeleiteten Datentyps mit einem Wert für
totalDigits von p
ist die Menge der Werte i × 10^-n, wobei n und i ganze Zahlen sind mit p >= n >= 0 und die Anzahl der signifikanten Dezimalstellen in i ist kleiner oder gleich p.
[Definition:]
Der Wertebereich eines von decimal abgeleiteten Datentyps mit einem Wert für fractionDigits von s
ist die Menge der Werte i × 10^-n, wobei i und n ganze Zahlen sind mit 0 <= n <= s.
3.2.3.1 Lexikalische Repräsentation
Die lexikalische Repräsentation des Datentyps decimal besteht aus
einer endlichen Sequenz von Ziffern (#x30-#x39) getrennt durch
einen Punkt, der sie als Dezimalzahl kenntlich
macht. Falls die Fassette totalDigits spezifiziert ist,
darf die Anzahl der Ziffern nur kleiner oder gleich wie in
totalDigits sein. Ist die Fassette
fractionDigits spezifiziert, muss die Anzahl der rechts
vom Punkt stehenden Ziffern kleiner oder gleich der Anzahl der
fractionDigits
sein. Ein Vorzeichen ist erlaubt, aber nicht erforderlich.
Ist kein Vorzeichen vorhanden, wird "+" angenommen. Führende und
nachfolgende Nullen sind ebenfalls optional. Ist der Bruchteil
Null, können sowohl der Punkt als auch die nachfolgenden Nullen
rechts vom Punkt weggelassen werden. Beispiele:
-1.23, 12678967.543233, +100000.00, 210
3.2.3.2 Kanonische Repräsentation
Die kanonische Repräsentation von decimal ist definiert, indem einige
der in der Lexikalische Repräsentation (§3.2.3.1)
vorhandenen Optionen verboten werden. Insbesondere ist
ein führendes "+"-Zeichen nicht gestattet. Ein Dezimalpunkt
ist zwingend. Führende oder nachfolgende Nullen sind
nicht zulässig bis auf folgende Ausnahme: Sowohl rechts als links vom Punkt
muss mindestens eine Ziffer stehen, die jedoch Null
sein darf.
3.2.4 float
[Definition:]
float entspricht dem einfach-genauen IEEE
32-Bit Datentyp einer Gleitkommazahl [IEEE 754-1985]. Der grundlegende Wertebereich von
float setzt sich aus den Werten m ×
2^e zusammen, wobei m
vom Datentyp integer ist, mit dem Absolutwert kleiner als 2^24, und e eine ganze Zahl zwischen -149 und 104, die Grenzen
eingeschlossen. Zusätzlich zum gerade beschriebenen Wertebereich enthält der Wertebereich von float noch die folgenden speziellen Werte: die positive und
negative Null, plus und minus unendlich sowie den Wert not-a-number (keine-Zahl).
Die Ordnungsbeziehung auf
den Datentyp float ist: x < y wenn y - x
positiv ist. Die positive Null ist größer als die negative
Null. Not-a-number ist nur mit sich selbst gleich und größer als alle
anderen float-Werte einschließlich plus unendlich.
Ein Literal im lexikalischen Bereich, das eine Dezimalzahl d darstellen soll, wird auf den
normalisierten Wert im Wertebereich von float abgebildet, der d im Sinne von [Clinger, WD (1990)] am nächsten liegt; liegt d
exakt zwischen zwei solchen Werten, dann wird der gerade Wert
gewählt.
3.2.4.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von float-Werten
besteht aus der Mantisse gefolgt von einem optionalen Buchstaben
"e" oder "E" und einem Exponenten. Der Exponent muss vom Typ integer
sein und die Mantisse vom Typ decimal. Die Darstellung von
Exponent und Mantisse muss den lexikalischen Regeln für integer und
decimal genügen. Wenn das "E" bzw. "e" und der
nachfolgende Exponent fehlen, wird der Wert des Exponenten mit 0 angenommen.
Die lexikalischen Repräsentationen für die speziellen Werte positive
und negative Null, plus und minus unendlich und not-a-number
lauten 0, -0, INF,
-INF und NaN.
Die folgenden Literale sind gültige Beispiele für float:
-1E4, 1267.43233E12, 12.78e-2, 12 und INF
3.2.4.2 Kanonische Repräsentation
Die kanonische Repräsentation von float wird definiert,
indem einige der in der Lexikalische Repräsentation (§3.2.4.1)
vorhandenen Optionen verboten werden. Insbesondere muss der
Exponent durch ein großes "E" eingeleitet werden. Führende Nullen
und das vorangestellte optionale "+"-Zeichen sind im
Exponenten nicht erlaubt. Das vorangestellte optionale
"+"-Zeichen ist in der Mantisse nicht erlaubt und der Dezimalpunkt ist
zwingend vorgeschrieben. Führende und folgende Nullen
sind nicht gestattet, mit folgenden Ausnahmen: Zahlendarstellungen
müssen nomalisiert sein, so dass links vom Dezimalpunkt
genau eine Ziffer steht und mindestens eine Ziffer rechts
vom Dezimalpunkt.
3.2.5 double
[Definition:]
double entspricht dem doppelt-genauen IEEE
64-Bit-Datentyp einer Gleitkommazahl [IEEE 754-1985]. Der grundlegende
Wertebereich von double setzt sich
aus Werten der Form m × 2^e zusammen,
dabei ist m vom Datentyp Integer mit einem
Absolutwert, der kleiner ist als 2^53, und e
ist ein Integer-Wert zwischen -1075 und 970, die Grenzen
eingeschlossen. Zusätzlich enthält der Wertebereich des Datentyps double noch die folgenden speziellen
Werte: eine positive und negative Null, minus und plus
unendlich und not-a-number. Die Ordnungsbeziehung auf double lautet:
x < y wenn y - x
positiv ist. Die positive Null ist größer als die negative
Null. Not-a-number ist nur mit sich selbst gleich und größer als alle
anderen double-Werte einschließlich plus unendlich.
Ein Literal im lexikalischen Bereich repräsentiert eine Dezimalzahl
d, die auf einen normalisierten Wert im
Wertebereich des Datentyps double abgebildet wird, der am nächsten bei d liegt;
liegt d genau zwischen zwei solchen
Werten, wird der gerade Wert gewählt. Dies ist die beste
Näherung von d ([Clinger, WD (1990)], [Gay, DM (1990)]), die genauer
ist als die in [IEEE 754-1985] geforderte Abbildung.
3.2.5.1 Lexikalische Repräsentation
Ein Wert des Datentyps double besteht aus einer
Mantisse, gefolgt von einem optionalen durch ein "E" oder "e"
eingeleiteten Exponenten. Der Exponent muss vom Datentyp integer sein. Die Mantisse
muss eine Dezimalzahl sein. Die Darstellungen für Mantisse und
Exponent müssen den lexikalischen Regeln für integer
und decimal gehorchen. Fehlen das "E" bzw. "e" und
der folgende Exponent, wird 0 als Exponent angenommen.
Die speziellen Werte positive und negative Null, plus
und minus unendlich sowie not-a-number haben die folgende lexikalische
Repräsentation: 0, -0, INF,
-INF und NaN.
Die folgenden Beispiele sind legale Literale für double: -1E4,
1267.43233E12, 12.78e-2, 12 und INF
3.2.5.2 Kanonische Repräsentation
Die kanonische Repräsentation von double ist definiert, indem einige
der in der Lexikalische Repräsentation (§3.2.5.1) vorhandenen Optionen verboten werden. Insbesondere muss der Exponent durch ein großes
"E" eingeleitet werden. Führende Nullen und vorangestellte optionale "+"-Zeichen sind im
Exponenten nicht erlaubt. Das vorangestellte optionale "+"-Zeichen ist in der Mantisse
nicht erlaubt und der Dezimalpunkt ist zwingend
vorgeschrieben. Vorangestellte und nachfolgende Nullen sind nicht
erlaubt, mit folgenden Ausnahmen: Zahlendarstellungen müssen
in der Form normalisiert werden, so dass links vom Dezimalpunkt genau eine
Ziffer und mindestens eine Ziffer rechts vom Dezimalpunkt steht.
3.2.6 duration
[Definition:] :
Der Datentyp duration stellt eine Zeitdauer dar. Der
Wertebereich von duration ist ein sechsdimensionaler Raum. Die
einzelnen Koordinatenteile bezeichnen das gregorianische Jahr,
Monat, Tag, Stunde, Minute und Sekunde, die in §5.5.3.2 in [ISO
8601] definiert sind. Diese Komponenten sind nach ihrer Signifikanz
geordnet, z. B. Jahr, Monat, Tag, Stunde, Minute, Sekunde.
3.2.6.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von duration ist das
in [ISO 8601] beschriebene erweiterte Format
PnYn MnDTnH
nMnS. Dabei stellt nY die Anzahl an
Jahren, nM die Anzahl an Monaten und nD die Anzahl an Tagen dar. "T"
trennt die Datums- und Zeitangabe. Die Anzahl an Stunden wird durch
nH, die der Minuten durch das zweite nM und die der Sekunden durch
nS dargestellt. Die Angabe zu Sekunden kann ggf. auch Dezimalstellen
enthalten und so beliebige Genauigkeiten erreichen.
Die Werte zu Jahr, Monat und Tag, Stunde und Minute sind nicht
eingeschränkt, sondern erlauben einen beliebigen Integer-Wert. Der
Wert für Sekunden kann ein beliebiger Dezimalwert sein. D.h. die
lexikalische Repräsentation von duration entspricht
nicht dem in §5.5.3.2.1 von [ISO 8601] vorgestellten
Format.
Um negative Zeitspannen darzustellen, kann einem duration-Wert ein
Minuszeichen vorangestellt werden. Fehlt das Minuszeichen, handelt
es sich um eine positive Zeitdauer. Vgl. auch ISO 8601 Datums- und Zeit-Formate (§D).
Um beispielsweise die Zeitspanne von 1 Jahr, 2 Monaten, 3 Tagen, 10 Stunden
und 30 Minuten darzustellen, würde die entsprechende Angabe wie
folgt aussehen: P1Y2M3DT10H30M. Eine Zeitspanne von
-120 Tagen hätte folgende Form: -P120D.
Es ist möglich, die Genauigkeit herabzusetzen oder die Darstellung zu
verkürzen, solange folgende Bedingungen erfüllt sind:
-
Sind die Angaben zu Jahren, Monaten, Tagen, Stunden, Minuten
oder Sekunden Null, können sie und ihr Bezeichner (z. B. Y nach der
Jahresangabe) weggelassen werden. Es muss mindestens eine Angabe
mit Bezeichner vorhanden sein.
-
Der Sekundenanteil kann durch einen Dezimalbruch angegeben werden.
-
Der T-Bezeichner sollte nicht erscheinen, wenn es keine
Zeitangaben (Stunde, Minute, Sekunde) gibt. Der P-Bezeichner ist
zwingend erforderlich.
Beispiele
| P1347Y, P1347M, P1Y2MT2H |
erlaubt |
| P0Y1347M, P0Y1347M0D |
erlaubt |
| P-1347M, P1Y2MT |
nicht erlaubt |
| -P1347M |
erlaubt |
3.2.6.2 Ordnungsbeziehung auf duration
Generell gibt die Ordnungsbeziehung auf
duration nur eine partielle Ordnung an, denn zwischen
bestimmten Zeitspannen, wie zum Beispiel einem Monat, gibt es keine festgelegte Beziehung,
z. B. ein Monat (P1M) und 30 Tage (P30D). Die Ordnungsbeziehung zwischen zwei Zeitspannen x und y ist: x < y, wenn s+x < s+y für jeden
qualifizierten Zeitstempel (dateTime) s aus der Liste unten gilt. Die Werte für s verursachen
die größten Abweichungen beim Addieren von Zeitstempeln (dateTime) und Zeitspannen (duration). Die Addition von
Zeitspannen und Zeitpunkten ist in "Addtion von Zeitspannen und
Zeitpunkten" definiert (Addition von Zeitspannen zu Zeitpunkten (§E)).
-
1696-09-01T00:00:00Z
-
1697-02-01T00:00:00Z
-
1903-03-01T00:00:00Z
-
1903-07-01T00:00:00Z
Die folgende Tabelle zeigt die stärkste festlegbare Beziehung zwischen
verschiedenen Beispielzeitspannen. Das Symbol < > bedeutet, dass die
Ordnungsbeziehung nicht festgelegt ist. {Beachten sie, dass das Sekunden-Feld
wegen der Schaltsekunden zwischen 59 und 60 variieren kann.} Durch die in §E
definierte Addition von Zeitspannen und Zeitpunkten sind diese immer
noch geordnet.
| |
Relation |
| P1Y
|
> P364D
|
<> P365D
|
|
<> P366D
|
< P367D
|
| P1M
|
> P27D
|
<> P28D
|
<> P29D
|
<> P30D
|
<> P31D
|
< P32D
|
| P5M
|
> P149D
|
<> P150D
|
<> P151D
|
<> P152D
|
<> P153D
|
< P154D
|
Implementierungen ist es freigestellt, Optimierungen
bei der Berechnung der Ordnungsbeziehung vorzunehmen.
So könnte beispielsweise die folgende Tabelle dazu verwendet
werden, Zeitintervalle über eine kleine Anzahl von Monaten mit deren Länge
in Tagen zu vergleichen.
| |
Months |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
... |
| Days |
Minimum |
28 |
59 |
89 |
120 |
150 |
181 |
212 |
242 |
273 |
303 |
334 |
365 |
393 |
... |
| Maximum |
31 |
62 |
92 |
123 |
153 |
184 |
215 |
245 |
276 |
306 |
337 |
366 |
397 |
... |
3.2.6.3 Fassetten von Zeitspannen vergleichen
Beim Vergleich von duration-Werten,
die minInclusive-, minExclusive-, maxInclusive- und maxExclusive-Fassetten
besitzen, sollten nicht definierte Vergleiche als "false"
angesehen werden.
3.2.6.4 Total geordnete Zeitspannen
Für einige der von duration abgeleiteten Datentypen
kann die Existenz einer totalen Ordnung garantiert werden. Damit dies
gilt, dürfen sie lediglich aus den
Feldern bestehen, die in nur einer Zeile der folgenden Liste
aufgeführt sind, und das Angeben der Zeitzone muss entweder zwingend
erforderlich oder verboten sein.
-
Jahr, Monat
-
Tag, Stunde, Minute, Sekunde
Beispielsweise könnte ein Datentyp als Entsprechung für das in [SQL]
definierte Jahr-Monat-Intervall definiert werden. Dieses
besteht lediglich aus einer vierstelligen Jahreszahl und einer zweistelligen
Monatszahl, alle anderen Felder sind nicht spezifiziert.
Dieser Datentyp könnte wie unten definiert sein und
würde eine totale Ordnung haben.
<simpleType name="SQL-Year-Month-Interval">
<restriction base="duration">
<pattern value="P\p{Nd}{4}Y\p{Nd}{2}M"/>
</restriction>
</simpleType>
3.2.7 dateTime
[Definition:]
dateTime stellt einen spezifischen Zeitpunkt dar. Der
Wertebereich von dateTime entspricht dem Raum von möglichen
Kombinationen aus Datum und Tageszeit wie in §5.4 von [ISO 8601]
definiert.
3.2.7.1 Lexikalische Repräsentation
Eine der in [ISO 8601] erlaubten lexikalischen
Repräsentationen wird als lexikalische Repräsentation für
dateTime verwendet. Dabei handelt es sich um das
erweiterte Format aus [ISO 8601]
CCYY-MM-DDThh:mm:ss. "CC" steht für das Jahrhundert (engl. Century),
"YY" für das Jahr, "MM" für den Monat und "DD" für den Tag. Der
Buchstabe "T" dient als Trennzeichen zwischen Datum und
Zeit. Stunden, Minuten und Sekunden werden durch "hh", "mm" und "ss"
repräsentiert. Zusätzliche Ziffern sind möglich, um bei Bedarf die
Genauigkeit der Sekunden durch weitere Dezimalstellen nach dem Punkt
zu erhöhen. Z.B. ss.ss... Es sind beliebig viele Dezimalstellen
zulässig. Der Teil der Sekunden nach dem Punkt ist optional, während
der Teil vor dem Punkt nicht optional ist. Für Jahreszahlen größer als 9999
können links weitere Stellen aufgenommen werden. Hat eine
Jahresangabe weniger als vier Stellen, muss diese links mit Nullen
aufgefüllt werden. Anderenfalls ist sie unzulässig.
Das Feld CCYY muss mindestens vier und die Felder MM, DD, SS, hh, mm und
ss exakt zwei Ziffern lang sein. Bei weniger als zwei Stellen müssen
die Felder mit Nullen aufgefüllt werden.
Dieser Darstellung kann direkt ein "Z" nachgestellt werden, um anzuzeigen, dass es sich um
die Coordinated Universal Time (UTC) handelt. Folgt der Zeitangabe
statt einem "Z" ein Plus- oder Minuszeichen, bedeutet das, dass
darauf folgende hh:mm die Differenz zur UTC angeben (der
Minutenanteil ist zwingend). In ISO 8601 Datums- und Zeit-Formate (§D)
findet man weitere Details zu gültigen Werten und verschiedenen
Feldern. Ist die Zeitzone mit angegeben, müssen Stunden und Minuten
auch angegeben werden.
Um z.B. den 31. Mai 1999 um 13:20h in der Zeitzone
Eastern Standard Time, die der UTC um 5 Stunden nachläuft, darzustellen, würde das
folgendermaßen geschrieben werden:
1999-05-31T13:20:00-05:00.
3.2.7.2 Kanonische Repräsentation
Die kanonische Repräsentation für dateTime ist
definiert, indem einige der wahlfreien Punkte der Lexikalische Repräsentation (§3.2.7.1)
eingeschränkt wurden. Das heißt explizit: Entweder wird
die Zeitzone nicht angegeben, oder wenn doch, muss die Zeitzone
UTC sein. Dies muss durch ein "Z" angegeben werden.
3.2.7.3 Ordnungsbeziehung auf dateTime
Allgemein gibt die Ordnungsbeziehung auf
dateTime eine partielle Ordnung an, da es bestimmte
dateTime-Instanzen
gibt, für die es keine festgelegte Beziehung gibt. So
gibt es beispielsweise keine Ordnung zwischen (a) 2000-01-20T12:00:00
und 2000-01-20T12:00:00Z. Basierend auf den aktuell
verwendeten Zeitzonen könnte (a) von 2000-01-20T12:00:00+12:00
bis 2000-01-20T12:00:00-13:00 variieren. Es ist jedoch
möglich, dass dieser Bereich in Zukunft auf Basis lokaler Gesetze vergrößert
oder verkleinert wird. Deshalb verwendet die folgende
Definition einen etwas breiteren Bereich von nicht festgelegten
Werten: +14:00...-14:00.
In der folgenden Definition wird die Notation S[Jahr] verwendet, um
das Jahresfeld einer dateTime darzustellen, S[Monat]
steht für das Monatsfeld usw. Die Notation (Q &
"-14:00") bedeutet, dass Q der Zeitzone -14:00
zugerechnet wird, wobei Q noch keine Zeitzone hat. Dies ist eine logische Erklärung des Ablaufs. Aktuellen Implementierungen ist es
freigestellt, zu optimieren, solange das Resultat dasselbe
bleibt.
Die Ordnung zwischen zwei dateTimes P und Q ist durch folgenden
Algorithmus definiert:
A. Normalisiere P und Q: Das bedeutet, dass Zeitzonen ungleich Z
nach Z konvertiert werden, indem die Additionsoperation verwendet
wird, die in "Addieren von duration und dateTimes" (§E)
definiert ist.
-
2000-03-04T23:00:00+03:00 ist normalisiert 2000-03-04T20:00:00Z
B. Falls P und Q entweder beide eine Zeitzone haben oder beide keine
haben, vergleiche P und Q Feld für Feld, angefangen beim Jahresfeld,
und liefere ein Ergebnis, sobald eines festgelegt werden kann, wie
folgt:
-
Für jedes i aus {Jahr, Monat, Tag, Stunde, Minute, Sekunde}
-
Falls P[i] und Q[i] beide nicht spezifiziert sind,
fahre fort mit nächstem i.
-
Falls P[i] nicht spezifiziert ist und Q[i] ist spezifiziert
oder umgekehrt, stoppen und (P <> Q) als Ergebnis zurückgeben.
-
Falls P[i] < Q[i], stoppen und (P < Q) als Ergebnis zurückgeben.
-
Falls P[i] > Q[i], stoppen und (P > Q) als Ergebnis
zurückgeben.
-
Stoppen und (P = Q) zurückgeben.
C. Anderenfalls, falls P eine Zeitzone enthält und Q nicht führe
folgende Vergleiche durch:
-
P < Q, falls P < (Q mit Zeitzone +14:00)
-
P > Q, falls P > (Q mit Zeitzone -14:00)
-
P <> Q anderenfalls, das heißt,
falls (Q mit Zeitzone +14:00) < P < (Q mit Zeitzone -14:00)
D. Anderenfalls, falls P keine Zeitzone enthält und Q enthält eine
Zeitzone, führe folgende Vergleiche:
-
P < Q, falls (P mit Zeitzone +14:00)
-
P > Q, falls (P mit Zeitzone -14:00)
-
P <> Q anderenfalls, das heißt,
falls (P mit Zeitzone +14:00) < Q < (P mit Zeitzone -14:00)
Beispiele:
| Determinate |
Indeterminate |
|
2000-01-15T00:00:00 < 2000-02-15T00:00:00
|
2000-01-01T12:00:00 <> 1999-12-31T23:00:00Z
|
|
2000-01-15T12:00:00 < 2000-01-16T12:00:00Z
|
2000-01-16T12:00:00 <> 2000-01-16T12:00:00Z
|
| |
2000-01-16T00:00:00 <> 2000-01-16T12:00:00Z
|
3.2.7.4 Total geordnete dateTimes
Für bestimmte von dateTime
abgeleitete Typen kann eine totale Ordnung garantiert
werden. Um das sicherstellen zu können, muss gefordert werden, dass bestimmte
Felder stets gesetzt und die anderen,
wenn noch übrig, stets nicht gesetzt sind. Z.B. enthält der Datentyp
date (Datum) ohne Zeitzone lediglich die Felder Jahr,
Monat und Tag. Darum haben dates ohne Zeitzone eine
totale Ordnung auf sich selbst.
3.2.8 time
[Definition:]
time repräsentiert eine Instanz der Zeit, die jeden Tag
wiederkehrt. Der Wertebereich von time entspricht dem Bereich
der Tageszeitwerte, die in §5.3 von [ISO 8601] definiert sind. Das
ist eine Menge von Tageszeitinstanzen mit der Dauer null.
Da die lexikalische Repräsentation die Angabe einer Zeitzone
freistellt, können time-Werte nur teilweise geordnet
werden, weil die Ordnung zwischen einem Wert mit und einem Wert ohne
Zeitzone nicht festgelegt werden kann. Die Ordnungsbeziehung auf
time entspricht der Ordnungsbeziehung auf dateTime
(§3.2.7.3) unter Verwendung eines beliebigen Datums. Siehe auch
Additionsoperation von duration und dateTime (§E). Paare von
time-Werten mit oder ohne Zeitzone sind total
geordnet.
3.2.8.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von time entspricht der
von dateTime ohne deren linken Teil: hh:mm:ss.sss mit einer
optionalen Zeitzonenangabe. Z.B. würde man 1:20 nachmittags zur
Eastern Standard Time, die 5 Stunden hinter der Coordinated
Universal Time (UTC) herläuft, schreiben: 13:20:00-05:00. Siehe auch
ISO 8601 Datums- und Zeit-Formate (§D).
3.2.8.2 Kanonische Repräsentation
Die kanonische Repräsentation von time ist definiert,
indem einige der Optionen der lexikalischen Repräsentation
(§3.2.8.1) verboten wurden. Die Zeitzone muss entweder
weggelassen werden oder der Coordinated Universal Time (UTC)
entsprechen, die durch ein "Z" ausgedrückt wird. Zusätzlich lautet
die kanonische Repräsentation für Mitternacht 00:00:00.
3.2.9 date
[Definition:]
date stellt ein Kalenderdatum dar. Der Wertebereich von
date ist eine Menge Kalenderdaten des gregorianischen Kalenders, gemäß Definition in § 5.4 von [ISO 8601]. Insbesondere ist es eine Menge von einen Tag langen, nicht periodischen
Instanzen. Beispielsweise repräsentiert lexikalisch 1999-10-26 das Kalenderdatum
26. Oktober 1999, unabhängig davon, wie viele Stunden ein Tag hat.
Da die lexikalische Repräsentation die Angabe einer Zeitzone
freistellt, können date-Werte nur teilweise geordnet
werden, weil es nicht möglich ist, die Ordnung zwischen einem Datum
mit und ohne Zeitzone ohne Mehrdeutigkeiten festzulegen. Falls
date-Werte als Zeitperioden zu verstehen sind, legt die
Ordnungsbeziehung auf date die Ordnung der Startwerte
fest. Das wird in Ordnungsbeziehung auf dateTime (§3.2.7.3)
erläutert. Siehe auch Addition von Zeitspannen und dateTime
(§E). Paare von date-Werten mit oder ohne Zeitzone
sind total geordnet.
3.2.9.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von date ist die
reduzierte (rechts abgeschnittene) lexikalische Repräsentation von
dateTime: CCYY-MM-DD. Links darf kein Feld abgeschnitten werden. Die
Angabe einer Zeitzone ist freistellt. Um Jahreszahlen mit mehr als
vier Stellen darstellen zu können, dürfen weitere Ziffern links
angefügt werden und ein vorangestelltes Minuszeichen ist erlaubt.
Um zum Beispiel den 31. Mai 1999 zu bezeichnen, würde man schreiben: 1999-05-31.
Siehe auch ISO 8601 Datums- und Zeit-Formate (§D).
3.2.10 gYearMonth
[Definition:]
gYearMonth repräsentiert einen bestimmten gregorianischen
Monat in einem bestimmten gregorianischen Jahr. Der Wertebereich von
gYearMonth ist die Menge aller Monate im gregorianischen
Kalender, wie in [ISO 8601]
§5.2.1 definiert. Dabei handelt es sich um bestimmte,
einen Monat lange, nicht periodische Instanzen. Zum Beispiel würde 1999-10
den kompletten Monat Oktober im Jahr 1999
repräsentieren, gleichgültig wie viele Tage dieser Monat hat.
Da die lexikalische Repräsentation die Angabe einer Zeitzone
erlaubt, gibt es keine vollständige Ordnungsbeziehung auf
gYearMonth, denn es ist nicht möglich, die Ordnung
zwischen zwei Werten anzugeben, von denen einer eine Zeitzonenangabe
hat und der andere nicht. Falls gYearMonth-Werte zur
Angabe von Zeitperioden verwendet werden, richtet sich die
Ordnungsbeziehung nach den Startwerten. Im Abschnitt §3.2.7.3
Ordnungsbeziehung auf dateTime wird das näher erläutert. Siehe auch
Addition von duration und dateTime (§E). Paare von
gYearMonth-Werten mit oder ohne Zeitzone sind total
geordnet.
Anmerkung:
Da Monat/Jahr-Kombinationen in einem Kalender nur selten mit
Monat/Jahr-Kombinationen in anderen Kalendern übereinstimmen, sind
sie normalerweise nicht in einfache Werte konvertierbar, die mit
Monat/Jahr-Kombinationen in anderen Kalendern
übereinstimmen. Dieser Typ sollte deshalb mit Vorsicht in Kontexten
eingesetzt werden, wo die Konvertierung in andere Kalender
gefordert ist.
3.2.10.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von gYearMonth ist eine
reduzierte (rechts abgeschnittene) lexikalische Repräsentation von
dateTime: CCYY-MM. Es ist nicht erlaubt, links Teile
abzuschneiden. Die Angabe einer Zeitzone ist erlaubt. Um
Jahreszahlen über 9999 darstellen zu können, dürfen links weitere
Stellen angefügt werden. Ein vorangestelltes Minuszeichen ist
erlaubt.
Um z.B. den Monat Mai im Jahr 1999 darzustellen, würde man
schreiben: 1999-05. Siehe auch ISO 8610 Date and Time Formats
(§D).
3.2.11 gYear
[Definition:]
gYear stellt ein Jahr im gregorianischen Kalender dar. Der
Wertebereich von gYear ist die Menge der Jahre im
gregorianischen Kalender, wie sie in [ISO 8601] §5.2 definiert
sind. Dabei handelt es sich um eine bestimmte, ein Jahr lange, nicht
periodische Instanz. Z.B. 1999 repräsentiert das Jahr 1999,
unabhängig davon, wie viele Monate das Jahr hat.
Da die lexikalische Repräsentation von gYear die Angabe
einer Zeitzone erlaubt, gibt es keine vollständige Ordnungsbeziehung
auf gYear, denn es ist nicht möglich, die Ordnung
zwischen zwei Werten anzugeben, von denen einer eine Zeitzonenangabe
hat und der andere nicht. Falls gYear zur Angabe von
Zeitperioden verwendet wird, richtet sich die Ordnung nach den
Startwerten. Im Abschnitt §3.2.7.3 Ordnungsbeziehung auf
dateTime wird das näher erläutert. Siehe auch Addition von duration
und dateTime (§E). Paare von gYear-Werten mit oder
ohne Zeitzone sind total geordnet.
Anmerkung:
Da Jahre in einem Kalender nur selten mit Jahren in anderen
Kalendern übereinstimmen, sind sie normalerweise nicht in einfache
Werte konvertierbar, die mit Jahren in anderen Kalendern
übereinstimmen. Dieser Typ sollte deshalb mit Vorsicht in Kontexten
eingesetzt werden, wo die Konvertierung in andere Kalender
gefordert ist.
3.2.11.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von gYear ist eine
reduzierte (rechts abgeschnittene) lexikalische Repräsentation von
dateTime: CCYY. Es ist nicht erlaubt, links Teile abzuschneiden. Die
Angabe einer Zeitzone ist erlaubt. Um Jahreszahlen über 9999
darstellen zu können, dürfen links weitere Stellen angefügt
werden. Ein vorangestelltes Minuszeichen ist erlaubt.
Um z.B. das Jahr 1999 darzustellen, würde man 1999 schreiben. Siehe
auch ISO 8610 Date and Time Formats (§D).
3.2.12 gMonthDay
[Definition:]
gMonthDay ist ein wiederkehrendes gregorianisches Datum,
genauer ein Tag eines Jahres, wie der 3. Mai. Sich willkürlich
wiederholende Daten werden von diesem Datentyp nicht
unterstützt. Der Wertebereich von gMonthDay ist die Menge von
Kalenderdaten, wie in §3 von [ISO 8601] definiert. Dabei handelt es
sich um eine Menge von jährlich wiederkehrenden, einen Tag dauernden
Instanzen.
Da die lexikalische Repräsentation von gMonthDay die
Angabe einer Zeitzone erlaubt, gibt es keine vollständige
Ordnungsbeziehung auf gMonthDay, denn es ist nicht
möglich, die Ordnung zwischen zwei Werten anzugeben, von denen einer
eine Zeitzonenangabe hat und der andere nicht. Falls
gMonthDay zur Angabe von Zeitperioden verwendet wird,
richtet sich die Ordnung nach den Startwerten. Im Abschnitt
§3.2.7.3 Ordnungsbeziehung auf dateTime wird das näher
erläutert. Siehe auch Addition von duration und dateTime
(§E). Paare von gMonthDay-Werten mit oder ohne
Zeitzone sind total geordnet.
Anmerkung:
Da Kombinationen von Tag und Monat in einem Kalender nur selten
mit entsprechenden Kombinationen in anderen Kalendern
übereinstimmen, sind sie normalerweise nicht in einfache Werte
konvertierbar, die mit der Kombinationen von Tag und Monat in
anderen Kalendern übereinstimmen. Dieser Typ sollte deshalb mit
Vorsicht in Kontexten eingesetzt werden, wo die Konvertierung in
andere Kalender gefordert ist.
3.2.12.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von gMonthDay ist die
links abgeschnittene lexikalische Repräsentation von date:
--MM-DD. Die Angabe einer Zeitzone ist erlaubt. Ein Vorzeichen ist
nicht gestattet. Es sind keine anderen Formate zulässig. Siehe auch
ISO 8610 Date und Time Formats (§D).
Dieser Datentyp kann dazu verwendet werden, einen bestimmten Tag
eines Monats darzustellen, um zum Beispiel auszudrücken, dass mein Geburtstag am 14. September ist.
3.2.13 gDay
[Definition:]
gDay ist ein wiederkehrender gregorianischer Tag, ein Tag in
einem Monat, wie der 5. eines Monats. Willkürlich wiederkehrende
Tage werden von diesem Datentyp nicht unterstützt. Der Wertebereich
von gDay ist eine Menge der Kalenderdaten, wie in
§3 von [ISO 8601] definiert. Dabei handelt es sich um eine
einen Tag lange periodische Instanz.
Mit diesem Datentyp werden bestimmte Tage eines Monats
dargestellt. So lässt sich z.B. ausdrücken, dass man am 15. jedes
Monats seinen Gehaltsscheck bekommt.
Da die lexikalische Repräsentation von gDay die Angabe
einer Zeitzone zulässt, gibt es keine vollständige Ordnung auf gDay,
denn es ist nicht möglich, die Ordnung zwischen zwei Werten
festzulegen, von denen einer eine Zeitzone hat und der andere
nicht. Falls gDay zur Angabe von Zeitperioden verwendet
wird, richtet sich die Ordnung nach dem Startwert. Im Abschnitt
§3.2.7.3 Ordnungsbeziehung auf dateTime wird das näher
erläutert. Siehe auch Addition von duration und Datentyp
(§E). Paare von gDay-Werten mit oder ohne Zeitzone
sind total geordnet.
Anmerkung:
Da Tage in einem Kalender nur selten mit Tagen in anderen
Kalendern übereinstimmen, sind Werte dieses Types nicht einfach
oder intuitiv auf andere Kalender übertragbar. Darum sollte dieser
Typ mit Vorsicht eingesetzt werden, wenn die Übertragbarkeit auf
andere Kalender gefordert ist.
3.2.13.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von gDay ist die links
abgeschnittene lexikalische Repräsentation von date: ---DD. Die
Angabe einer Zeitzone ist erlaubt. Ein Vorzeichen ist nicht
zulässig. Andere Darstellungsarten sind nicht erlaubt. Siehe auch
ISO 8610 Date und Time Formats (§D).
3.2.14 gMonth
[Definition:]
gMonth ist ein gregorianischer Monat, der jedes Jahr
wiederkehrt. Der Wertebereich von
gMonth ist die Menge der Kalendermonate, wie sie in
§3 von [ISO 8601] definiert sind. Es handelt sich
um eine Menge von einen Monat langen, sich jährlich
wiederholenden Instanzen.
Dieser Datentyp kann verwendet werden, um einen bestimmten Monat
darzustellen, um z.B. auszudrücken, dass Weihnachten im Dezember
ist.
Da die lexikalische Repräsentation von gMonth die
Angabe einer Zeitzone erlaubt, gibt es keine vollständige
Ordnungsbeziehung auf gMonth, denn es ist nicht
möglich, die Ordnung zwischen zwei Werten anzugeben, von denen einer
eine Zeitzonenangabe hat und der andere nicht. Falls
gMonth zur Angabe von Zeitperioden verwendet wird,
richtet sich die Ordnung nach den Startwerten. Im Abschnitt
§3.2.7.3 Ordnungsbeziehung auf dateTime wird das näher
erläutert. Siehe auch Addition von duration und dateTime
(§E). Paare von gMonth-Werten mit oder ohne
Zeitzone sind total geordnet.
Anmerkung:
Da Monate in einem Kalender nur selten mit Monaten in anderen
Kalendern übereinstimmen, sind Werte dieses Types nicht einfach
oder intuitiv auf andere Kalender übertragbar. Darum sollte
dieser Typ mit Vorsicht eingesetzt werden, wenn die
Übertragbarkeit auf andere Kalender gefordert ist.
3.2.14.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von gMonth entspricht
der sowohl links als auch rechts abgeschnittenen lexikalischen
Repräsentation von date: --MM--. Die Angabe einer Zeitzone ist
erlaubt. Ein Vorzeichen ist nicht zulässig. Andere Darstellungsarten
sind nicht erlaubt. Siehe auch ISO 8610 Date und Time Formats
(§D). Andere Darstellungsarten sind nicht erlaubt. Siehe auch
ISO 8610 Date und Time Formats (§D).
3.2.15 hexBinary
[Definition:]
hexBinary repräsentiert hexadezimal kodierte Daten. Der
Wertebereich von hexBinary ist die Menge von
Oktettsequenzen endlicher Länge.
3.2.15.1 Lexikalische Repräsentation
In der lexikalischen Repräsentation von hexBinary wird
jedes Oktett mit zwei Zeichen aus [0-9a-fA-F]
dargestellt. Z.B. ist "0FB7" die hexadezimale Kodierung der
16-Bit-Integer-Zahl 4023 (binär 111110110111).
3.2.15.2 Kanonische Repräsentation
Zur Definition der kanonischen Repräsentation wurde die lexikalische
Repräsentation in bestimmten Punkten eingeschränkt. Das bedeutet,
dass die Kleinbuchstaben [a-f] nicht erlaubt sind.
3.2.16 base64Binary
[Definition:]
base64Binary stellt binäre Daten
Base64-kodiert dar. Der Wertebereich von
base64Binary ist die Menge von
Oktettsequenzen endlicher Länge. Für base64Binary wird der gesamte binäre Datenstrom unter Verwendung der Base64 Content Transfer Encoding nach Definition in Sektion 6.8 von
[RFC 2045] kodiert.
3.2.17 anyURI
[Definition:]
anyURI stellt einen Uniform Resource Identifier (URI)
dar. Ein anyURI-Wert kann absolut oder relativ sein und darf
Fragment-Bezeichner enthalten (z.B. könnte es eine URI-Refenz
sein). Dieser Datentyp sollte verwendet werden, um kenntlich zu
machen, dass der Wert die Regeln erfüllt, die in [RFC 2396]
definiert und in [RFC 2732] berichtigt sind.
Die Abbildung von anyURI-Werten auf URIs ist in
Abschnitt 5.4 Locator-Attribute der [XML 1.0 (Second Edition)] (siehe auch Abschnitt 8: Zeichen-Kodierung in
URI-Referenzen von [Character Model]). Das bedeutet,
dass mit einem anyURI eine große Bandbreite an
internationalisierten Ressourcen-Bezeichnern abgedeckt werden kann
und immer noch als URI im Sinne von [RFC 2396]
(berichtigt von [RFC 2732]) verstanden wird.
Anmerkung:
Für jedes URI-Schema gibt es spezielle Syntaxregeln, nach denen
ein URI dieses Schemas gebildet werden muss. Das schließt die
Syntax von zulässigen Fragment-Bezeichnern ein. Weil es für einen
Prozessor nicht praktikabel wäre, nachzuprüfen, ob eine
URI-Refenrenz ihrem Kontext gemäß verwendet wird, folgt diese
Spezifikation den Vorgaben von
[RFC 2396] (berichtigt
von
[RFC 2732]) auf folgende Weise: Solche Regeln und
Restriktionen sind nicht Teil der Gültigkeit und werden von
Prozessoren mit minimaler Unterstützung nicht
geprüft. Somit wird
Prozessoren mit minimaler Unterstützung nur ein sehr bescheidenes
Pflichtprogramm abverlangt.
3.2.17.1 Lexikalische Repräsentation
Der lexikalische Bereich von anyURI ist eine endlich
lange Zeichenkette, die einem legalen URI entspricht, wenn ein
Prüfalgorithmus vorliegt, der in Abschnitt 5 von [RFC 2396] (berichtigt von [RFC 2732]) definiert ist.
Anmerkung:
Leerzeichen sind prinzipiell zulässig im lexikalischen Bereich von
anyURI, sie sollten allerdings vermieden werden
(stattdessen sollte %20 verwendet werden).
3.2.18 QName
[Definition:]
QName stellt XML-qualifizierte Namen dar. Der
Wertebereich ist eine Menge von Tupeln der Form {Namespace-Name,
Lokal-Teil}. Dabei ist der Namespace-Name ein URI und der Lokal-Teil
ein NCName. Der lexikalische Bereich von QName ist die Menge
von Zeichenketten, die der QName-Produktion von [XML 1.0 (Second Edition)]
entsprechen.
Anmerkung:
Die Abbildung von Literalen im
lexikalischen Bereich
auf Werte im
Wertebereich von
QName verlangt eine Deklaration des Namespaces im
Sichtbarkeitsbereich, indem
QName verwendet wird.
3.2.19 NOTATION
[Definition:]
NOTATION stellt den Attributtyp NOTATION aus [XML 1.0 (Second Edition)] dar. Der Wertebereich von
NOTATION ist die Menge QNames. Der lexikalische
Bereich von NOTATION ist die Mengen aller
Notationsnamen, die im aktuellen Schema deklariert sind.
Schema Komponenten Beschränkung:
Vorausgesetzter Wert für die enumeration-Fassette von NOTATION
Es ist ein Fehler, wenn NOTATION direkt
in einem Schema verwendet wird. Nur Datentypen, die von
NOTATION abgeleitet sind, indem sie einen Wert für
enumeration spezifizieren, dürfen verwendet werden.
Aus Kompatibilitätsgründen sollte NOTATION nur in
Attributen benutzt werden (siehe Terminologie §1.4).
3.3 Abgeleitete Datentypen
Dieser Abschnitt liefert eine konzeptionelle Definition aller
abgeleiteten vordefinierten Datentypen in dieser Spezifikation. Die
XML-Repräsentation zur Definition von abgeleiteten
Datentypen (entweder vordefiniert oder
benutzerdefiniert) wird im Abschnitt §4.1.2
XML-Repräsentation einfacher Schema-Komponenten zur Typ-Definition
beschrieben. Die vollständigen Definitionen der
abgeleitetenvordefinierten Datentypen wird in
Anhang A geprüft (normativ) (§A).
3.3.1 normalizedString
[Definition:]
normalizedString stellt eine von Leerraum bereinigte Zeichenkette dar. Der Wertebereich von
normalizedString ist die Menge der Zeichenketten, die weder
carriage return (Wagenrücklauf) (#xD), line feed (Zeilenvorschub)
(#xA) noch Tabulatorzeichen (#x9) enthalten. Der lexikalischer Bereich von normalizedString ist die Menge der
Zeichenketten, die weder carriage return, line feed noch
Tabulatorzeichen enthalten. Der Basistyp von
normalizedString ist string.
3.3.2 token
[Definition:]
token stellt in Tokens übersetzte Zeichenketten
dar. Der Wertebereich von token ist
die Menge von Zeichenketten, die kein carriage return (#xD), kein
line feed (#xA) und kein Tabulatorzeichen (#x9) sowie am Anfang und
Ende keine Leerzeichen (#x20) enthalten, und auch im Inneren der
Zeichenkette folgen Leerzeichen nicht nacheinander. Der
lexikalische Bereich von token ist die
Menge der Zeichenketten, die kein carriage return, kein line feed
und keine Tabulatorzeichen enthalten, weder mit Leerzeichen beginnen
noch enden und auch im Inneren der Zeichenketten keine
Leerzeichenfolgen enthalten, die länger sind als zwei oder mehr Leerzeichen.
3.3.3 language
[Definition:]
language repräsentiert Bezeichner für natürliche
Sprachen, wie sie in [RFC 1766] definiert werden. Der
Wertebereich von language ist die
Menge aller Zeichenketten, die einen gültigen Bezeichner einer
natürlichen Sprache darstellen, wie sie im Abschnitt language
identification von [XML 1.0 (Second Edition)] definiert
werden. Der lexikalische Bereich von
language ist die Menge aller Zeichenketten, die einen
gültigen Bezeichner einer natürlichen Sprache darstellen, wie sie im
Abschnitt language identification von [XML 1.0 (Second Edition)] definiert
werden.
3.3.10 IDREFS
[Definition:]
IDREFS ist die Repräsentation des IDREFS-Attributs aus
[XML 1.0 (Second Edition)]. Der Wertebereich von IDREFS ist die Menge der
endlich langen, mindestens einen Eintrag enthaltenden Sequenzen von
IDREFs. Der lexikalische Bereich von
IDREFS ist die Menge von Token-Listen, deren Einträge
durch Leerräume separiert sind und in den lexikalischer Bereich
von IDREF gehören. Der itemType von NMTOKENS ist IDREF.
Aus Kompatibilitätsgründen (siehe Terminologie (§1.4)) sollte
IDREFS nur auf Attributen verwendet werden.
3.3.11 ENTITY
[Definition:]
ENTITY repräsentiert den ENTITY-Attribut-Typ aus
[XML 1.0 (Second Edition)]. Der lexikalische
Bereich von ENTITY ist die Menge aller
Zeichenketten, die der NCName-Produktion in [XML 1.0 (Second Edition)]
entsprechen und als ungeparste Entity in der
Document Type Definition deklariert sind. Der lexikalische
Bereich von ENTITY ist die Menge aller
Zeichenketten, die der NCName-Produktion in [Namespaces in XML]
entsprechen. Der Basistyp von
ENTITY ist NCName.
Anmerkung:
Die Sichtbarkeit des
Wertebereichs von
ENTITY
ist auf ein spezifisches Dokument begrenzt.
Aus Kompatibilitätsgründen (siehe Terminologie (§1.4)) sollte
ENTITY nur auf Attributen verwendet werden.
3.3.12 ENTITIES
[Definition:]
ENTITIES repräsentiert den ENTITIES-Attribut-Typ von
[XML 1.0 (Second Edition)]. Der Wertebereich von ENTITIES ist die Menge von
endlich langen , mindestens einen Eintrag enthaltenden Sequenzen von
ENTITYs, die als ungeparste Entität in der Document
Type Definition deklariert sind. Der lexikalische
Bereich von
ENTITIES ist die Menge von Token-Listen, deren Einträge
durch Leerraum sind und in den lexikalischen
Bereich von ENTITY gehören. Der itemType von
ENTITIES ist ENTITY.
Anmerkung:
Die Sichtbarkeit des
Wertebereichs von
ENTITIES ist auf ein spezifisches Dokument begrenzt.
Aus Kompatibilitätsgründen (siehe Terminologie (§1.4)) sollte
ENTITIES nur auf Attributen verwendet werden.
3.3.13 integer
[Definition:]
integer ist von decimal abgeleitet, in
dem der Wert von fractionDigits fest auf 0 gesetzt
wurde. Das Ergebnis ist das mathematische Standardkonzept der ganzen
Zahlen (integer numbers). Der Wertebereich von
integer ist die unendliche Menge { ..., -2, -1, 0, 1,
2, ... }. Der Basistyp von integer ist
decimal.
3.3.13.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von integer besteht aus
einer endlich langen Sequenz von Dezimalziffern (#x30-#x39) und
optional einem vorangestellten Vorzeichen. Falls kein Vorzeichen
vorhanden ist, wird "+" angenommen. Beispiele sind: -1, 0,
12678967543233, +100000.
3.3.13.2 Kanonische Repräsentation
Um die kanonische Repräsentation von integer zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.13.1) eingeschränkt. Sowohl ein führendes "+" als
auch führende Nullen sind nicht erlaubt.
3.3.14 nonPositiveInteger
[Definition:]
nonPositiveInteger ist von integer
abgeleitet, indem der Wert von
maxInclusive fest auf 0 gesetzt wurde. Das Ergebnis ist
das mathematische Standardkonzept der nicht positiven ganzen Zahlen
(non-positive integers). Der Wertebereich von
nonPositiveInteger ist die unendliche Menge { ..., -2,
-1, 0 }. Der Basistyp von
nonPositiveInteger ist integer.
3.3.14.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von nonPositiveInteger
besteht aus einem negativen Vorzeichen ("-") gefolgt von einer
endlich langen Sequenz von Dezimalziffern (#x30-#x39). Besteht die
Ziffernsequenz ausschließlich aus Nullen, ist das Vorzeichen
optional. Beispiele sind: -1, 0, -12678967543233, -100000.
3.3.14.2 Kanonische Repräsentation
Um die kanonische Repräsentation von nonPositiveInteger
zu definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.14.1) eingeschränkt. Das negativen
Vorzeichen ("-") ist auch beim Token "0" anzugeben und führende
Nullen sind nicht erlaubt.
3.3.15 negativeInteger
[Definition:]
negativeInteger ist von nonPositiveInteger abgeleitet, indem der Wert für maxInclusive fest auf -1
gesetzt wurde. Das Ergebnis ist das mathematische Standardkonzept
für negative ganze Zahlen. Der Wertebereich von
negativeInteger ist die unendliche Menge { ..., -2, -1 }. Der
Basistyp ist nonPositiveInteger.
3.3.15.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von negativeInteger
besteht aus einem negativen Vorzeichen ("-") gefolgt von einer
endlich langen Sequenz von Dezimalziffern (#x30-#x39). Beispiele
sind: -1, -12678967543233, -100000.
3.3.15.2 Kanonische Repräsentation
Um die kanonische Repräsentation von nonPositiveInteger zu
definieren,werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.15.1) eingeschränkt. Das bedeutet, dass führende
Nullen nicht erlaubt sind.
3.3.16 long
long ist von integerabgeleitet, indem
der Wert von maxInclusive fest auf 9223372036854775807
und der von minInclusive fest auf -9223372036854775808
gesetzt wurde. Der Basistyp von long ist
integer.
3.3.16.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von long besteht aus
einer endlich langen Sequenz von Dezimalziffern (#x30-#x39) und
optional einem vorangestellten Vorzeichen. Falls kein Vorzeichen
vorhanden ist, wird "+" angenommen. Beispiele sind: -1, 0,
12678967543233, +100000.
3.3.16.2 Kanonische Repräsentation
Um die kanonische Repräsentation von long zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.16.1) eingeschränkt. Ein führendes "+" als
auch führende Nullen sind nicht erlaubt.
3.3.17 int
[Definition:]
int ist von long abgeleitet, indem der
Wert von maxInclusive fest auf 2147483647 und der von
minInclusive fest auf -2147483648 gestetzt wurde. Der
Basistyp von int ist long.
3.3.17.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von int besteht aus
einer endlich langen Sequenz von Dezimalziffern (#x30-#x39) und
optional einem vorangestellten Vorzeichen. Falls kein Vorzeichen
vorhanden ist, wird "+" angenommen. Beispiele sind: -1, 0,
12678967543233, +100000.
3.3.17.2 Kanonische Repräsentation
Um die kanonische Repräsentation von int zu definieren,
werden einige der wahlfreien Punkte der lexikalischen Repräsentation
(§3.3.17.1) eingeschränkt. Ein führendes "+", sowie führende
Nullen sind nicht erlaubt.
3.3.18 short
[Definition:]
short ist
von int abgeleitet, indem der
Wert von maxInclusive fest auf 32767 und der von
minInclusive fest auf -32768 gesetzt wurde. Der
Basistyp von short ist int.
3.3.18.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von short besteht aus
einer endlich langen Sequenz von Dezimalziffern (#x30-#x39) und
optional einem vorangestellten Vorzeichen. Falls kein Vorzeichen
vorhanden ist, wird "+" angenommen. Beispiele sind: -1, 0, 12678,
+10000.
3.3.18.2 Kanonische Repräsentation
Um die kanonische Repräsentation von short zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.17.1) eingeschränkt. Ein führendes "+" und führende Nullen sind nicht erlaubt.
3.3.19 byte
[Definition:]
byte ist von int abgeleitet, indem der
Wert von maxInclusive fest auf 127 und der von
minInclusive fest auf -128 gesetzt wurde. Der
Basis-Typ von byte ist short.
3.3.19.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von byte besteht aus
einer endlich langen Sequenz von Dezimalziffern (#x30-#x39) und
optional einem vorangestellten Vorzeichen. Falls kein Vorzeichen
vorhanden ist, wird "+" angenommen. Beispiele sind: -1, 0, 126,
+100.
3.3.19.2 Kanonische Repräsentation
Um die kanonische Repräsentation von byte zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.18.1) eingeschränkt. Ein führendes "+", ebenso wie führende Nullen sind nicht erlaubt.
3.3.20 nonNegativeInteger
[Definition:]
nonNegativeInteger ist von von integer
abgeleitet, indem der Wert von
minInclusive fest auf 0 gesetzt wurde. Der Wertebereich von nonNegativeInteger ist die
unendliche Menge { 0, 1, 2. ... }. Der Basistyp von
nonNegativeInteger ist integer.
3.3.20.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von nonNegativeInteger
besteht aus einer endlich langen Sequenz von Dezimalziffern
(#x30-#x39) und optional einem vorangestellten Vorzeichen. Falls
kein Vorzeichen vorhanden ist, wird "+" angenommen. Beispiele sind:
1, 0, 12678967543233, +100000.
3.3.20.2 Kanonische Repräsentation
Um die kanonische Repräsentation von nonNegativeInteger
zu definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.20.1) eingeschränkt. Ein führendes "+" und führende Nullen sind nicht erlaubt.
3.3.21 unsignedLong
[Definition:]
unsignedLong ist von nonNegativeInteger
abgeleitet, indem der Wert von
maxInclusive fest auf 18446744073709551615 gesetzt
wurde. Der Basistyp von unsignedLong ist
nonNegativeInteger.
3.3.21.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von unsignedLong
besteht aus einer endlich langen Sequenz von Dezimalziffern
(#x30-#x39). Beispiele sind: 0, 12678967543233, +100000.
3.3.21.2 Kanonische Repräsentation
Um die kanonische Repräsentation von unsignedLong zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.21.1) eingeschränkt. Führende Nullen sind
nicht erlaubt.
3.3.21.4 Abgeleitete Datentypen
3.3.22 unsignedInt
[Definition:]
unsignedInt ist von unsignedLong
abgeleitet, indem der Wert von
maxInclusive fest auf 4294967295 gesetzt wurde. Der
Basistyp von unsignedInt ist unsignedLong.
3.3.22.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von unsignedInt besteht
aus einer endlich langen Sequenz von Dezimalziffern
(#x30-#x39). Beispiele sind: 0, 1267896754, +100000.
3.3.22.2 Kanonische Repräsentation
Um die kanonische Repräsentation von unsignedInt zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.22.1) eingeschränkt. Führende Nullen sind
nicht erlaubt.
3.3.23 unsignedShort
[Definition:]
unsignedShort ist von unsignedInt
abgeleitet, indem der Wert von
maxInclusive fest auf 65536 gesetzt wurde. Der
Basistyp von unsignedShort ist unsignedInt.
3.3.23.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von unsignedInt besteht
aus einer endlich langen Sequenz von Dezimalziffern
(#x30-#x39). Beispiele sind: 0, 12678, 10000.
3.3.23.2 Kanonische Repräsentation
Um die kanonische Repräsentation von unsignedInt zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.23.1) eingeschränkt. Führende Nullen sind
nicht erlaubt.
3.3.24 unsignedByte
[Definition:]
unsignedByte ist von unsignedShort
abgeleitet, indem der Wert von
maxInclusive fest auf 255 gesetzt wurde. Der
Basistyp von unsignedByte ist
unsignedShort.
3.3.24.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von unsignedByte
besteht aus einer endlich langen Sequenz von Dezimalziffern
(#x30-#x39). Beispiele sind: 0, 126, +100.
3.3.24.2 Kanonische Repräsentation
Um die kanonische Repräsentation von unsignedByte zu definieren,
werden einige der wahlfreien Punkte der lexikalischen Repräsentation
(§3.3.24.1) eingeschränkt. Führende Nullen sind nicht erlaubt.
3.3.25 positiveInteger
[Definition:]
positiveInteger ist von nonNegativeInteger
abgeleitet, indem der Wert von
minInclusive fest auf 1 gesetzt wurde. Das Ergebnis ist
das mathematische Standardkonzept der positiven ganzen Zahlen
(positive integers). Der Wertebereich von
positiveInteger ist die unendliche Menge { 1, 2,
... }. Der Basistyp von positiveInteger
ist nonNegativeInteger.
3.3.25.1 Lexikalische Repräsentation
Die lexikalische Repräsentation von positiveInteger besteht aus
einem optionalen positiven Vorzeichen ("+") gefolgt von einer endlich
langen Sequenz von Dezimalziffern ((#x30-#x39). Beispiele sind: 1,
12678967543233, +100000.
3.3.25.2 Kanonische Repräsentation
Um die kanonische Repräsentation von positiveInteger zu
definieren, werden einige der wahlfreien Punkte der lexikalischen
Repräsentation (§3.3.25.1) eingeschränkt. Ein führendes "+", sowie
führende Nullen sind nicht erlaubt.